This post follows up on a previous regression analysis, which used fitted several regression model types (nlm, logi, log2) to the data concerning monoallelic expression, and the effect of age and other explanatory variables. The goal here is to compare these models to select the one(s) with the most desirable properties.
Preparations
source("../2016-04-22-glm-for-s-statistic/2016-04-22-glm-for-s-statistic.R")
source("../2016-04-22-glm-for-s-statistic/2016-04-22-glm-for-s-statistic-run.R")
source("../2016-04-22-glm-for-s-statistic/2016-04-22-glm-for-s-statistic-graphs.R")
source("2016-05-07-comparing-regression-models.R")
Comparing models using AIC
AIC: criterion for model fit and parsimony
For any statistical model with parameter vector Akaike information criterion (AIC) is defined as The first term is the maximized log likelihood and quantifies how well the model fits the data (the higher the better fit). Here is the maximum likelihood estimate (m.l.e.) of . The second term is the number of parameters (i.e. the dimension of the vector ); the fewer parameters the model has the more parsimoniously it describes the data. Thus models with better fit and more parsimony have smaller AIC.
Since is a negative function and , AIC must be positive. However, the estimated AIC may be negative if the estimated is biased.
Biased AICs for normal linear models
The figure compares all three model families using estimated AIC. nlm.S, the normal linear model fit to untransformed has negative AIC values indicating bias in the AIC estimation and casting doubt on the utility of such biased AIC values in model comparison.
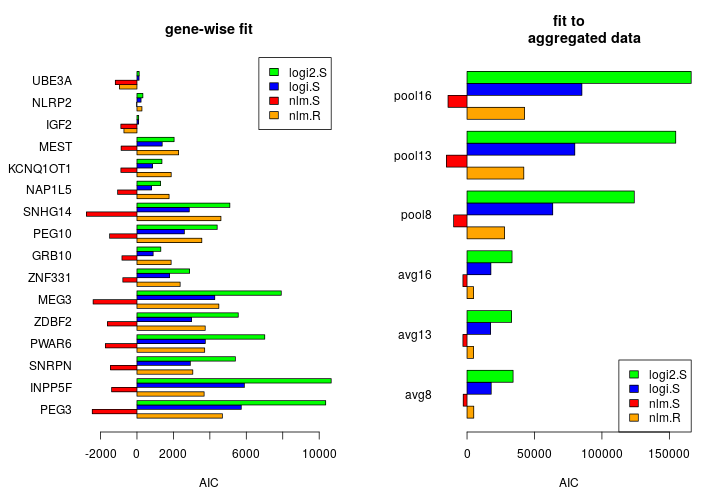
The biased AIC is due to biased log-likelihood estimates. For instance, the nlm.S fit to the PEG3 data has 1251 resulting in an estimated AIC of -2455. Such positive is impossible unless it is massively overestimated. Next I provide explanation and empirical evidence for such overestimation.
An explanation for bias
Theory
For a normal linear model the parameters consist the regression coefficients and error variance so . Error in this context is the difference between the response and its predicted value based on a fitted model. The maximum likelihood estimates are the so-called least square estimates because they are obtained from minimizing the sum of squares using the response of observations and the design matrix of explanatory variables. In this case (or after rank transformation), and means individuals/tissue samples. The log-likelihood for with fixed at the least square estimate is
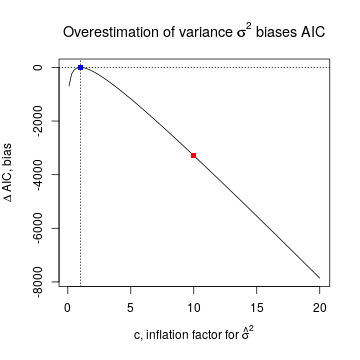
The m.l.e. for is . This is a good estimator when the variance of the errors is constant (across observations), which is one of the assumptions behind the nlm. But when that assumption is violated, the sum of squares is inflated (since it is a quadratic function of the error terms) and therefore is inflated. Suppose , where is an inflation factor and is the true variance. Then the biased estimation of also biases the estimated AIC by
For example, corresponds to an order of magnitude inflation in estimated variance. Then -3288 under the nlm.S model, indicated by the red square in the plot below. A negative shift of this magnitude may readily explain why the estimated AIC is negative. On the other hand means no inflation, in which case AIC is unbiased (blue square).
Empirical support
An indication that is largely inflated comes from the observation that it is close to the observed total variance of the response. For example, when the nlm is fitted to the untransformed PEG3 data, 3.64 × 10-4, only slightly smaller than the total variance of 4.28 × 10-4.
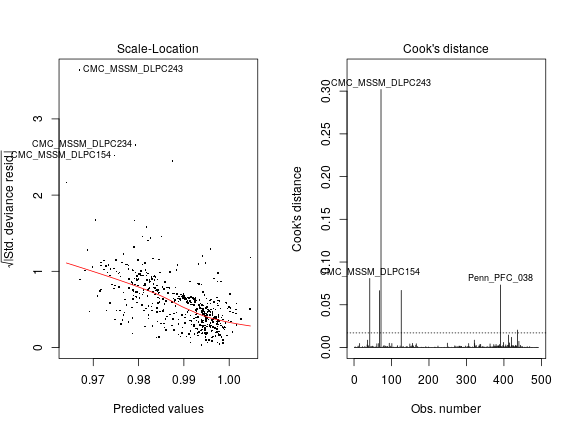
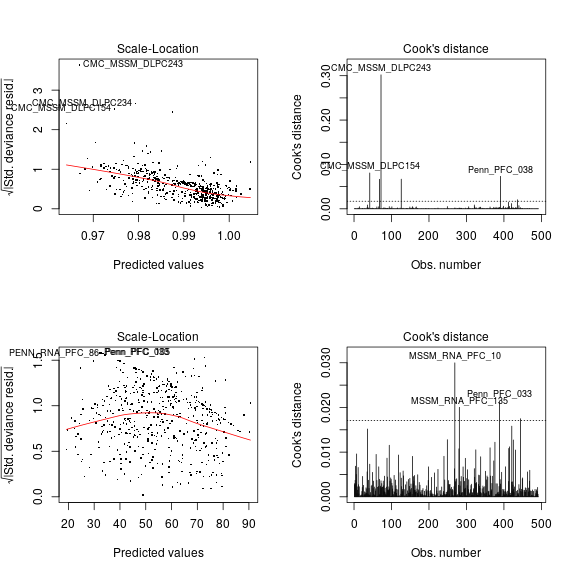
Still with PEG3 as an example, let’s check the constant variance assumption behind the nlm! The left panel shows strong systematic variation of the square root of standardized deviance (closely related to variance) with the predicted value of for each individual . The right panel demonstrates several extreme outliers, like the tissue sample CMC_MSSM_DLPC243, whose impact on biasing the least square estimate is quantified by Cook’s distance . A rule of thumb is that observations for which are “worth a closer look” (Davison: Statistical Models p395). In this example for CMC_MSSM_DLPC243 and for several other observations greatly exceeds 0.0171, marked by the horizontal dashed line (right panel).
Thus, we see a strong systematic and non-systematic departures from constant variance assumed by normal linear models; this departure may be sufficient to explain the gross overestimation of the maximum log-likelihood.
Rank transformation
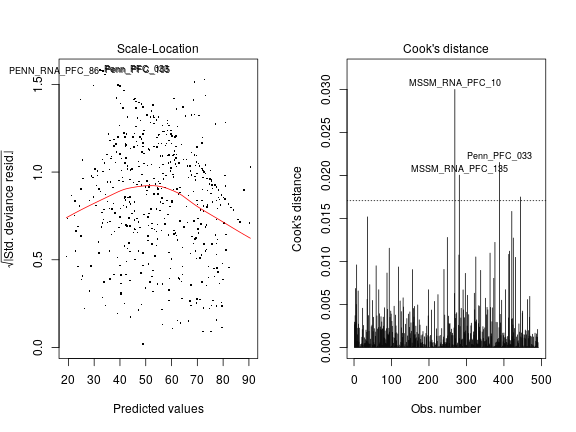
Transformations in general may help achieve the assumptions made by normal linear models on the data. The rank transformation dramatically improves the situation as shown below for PEG3. There seems to be not much systematic variation of variance with predicted values (left panel) and Cook’s distance for outliers does not greatly exceed the dashed line (right panel).
The rank transformation greatly improves also other properties of the data such as normality of errors, shown in the normal probability plots below (for PEG3; left panel: nml.S; right panel: nml.R).

Thus the normal linear model seems to fit well to the rank transformed data. In agreement with this, the estimated AIC is plausibly positive under nlm.R; it is 4688, thus not far from 5725 under logi.S, that is the logistic model fitted on untransformed . Based on the AIC for all 16 single gene fits, the nlm.R and logi.S models show comparable performance.
Figure for manuscript
Top panels: untransformed statistic; bottom panels: rank-transformed into
Utility-based comparison
Model fit and parsimony are not the only criteria for comparing models. In this section I examine the utility of model types pertaining to the following goals of the project:
- detect significant effect of age on parental bias (i.e. significant “loss of imprinting”)
- quantify the effect size of age
- improve classification by correcting for confounding explanatory variables (institution, RNA quality,…)
As we will see, different models have different limitations
Limitations of nlm.R
The results above show that rank transformation, denoted here as , is beneficial because the assumptions of the normal linear model are met in the case of rank transformed responses but not in the case of untransformed . With rank transformation, however, all information on effect size (of age, for instance) is lost. Also lost is any information on the baseline or average , which is essential for classifying gene as mono or biallelically expressing.
The plots below illustrate this limitation of rank transformation. Consider an affine transformation so that scales down the response by and shifts the baseline by (compare upper left and right panels). The downscaling of response simulates weakening effects of explanatory variables although somewhat unrealistically the variance of the error is also downscaled. The negative shift in baseline simulates changing the class of a monoallelically expressed gene (in this case PEG3) to biallelically expressing. But when rank transformation is applied to the two very different data sets shown on the top, all differences disappear (compare bottom left and right panels).
![]()
Limitations of logistic models logi.S, logi2.S
For this point I will consider separately two classes of genes
- monoallelically expressed (including the 16 known imprinted genes in the present data)
- biallelically expressed
Conclusions
TODO